Case Study
Statsbomb Sports Data Collection
2018-2022: What if 1000 collectors could work concurrently without choosing between speed and correctness?
TL;DR: What We Built (2 min)
Built real-time sports data collection with Ali from week one sketches to 5000+ collectors across multiple sports. When Hudl acquired Statsbomb in 2024, they bought the collection infrastructure—the system that made concurrent data capture possible at broadcaster scale. What started as “my hand doesn’t cramp anymore” feedback became the foundation for industry-standard tooling.
Origins: Week One Partnership
StatsBomb (Arqam) employed hundreds of soccer analysts—called collectors—who manually tracked every pass, shot, tackle, and positioning during live matches. Video analysis, frame by frame, translated into structured data for professional teams.
Early days, we shipped twice daily. Every morning, I’d push a new build of the FreezeFrame tool—replacing Dartfish’s 12-minute manual clicking with computer vision-assisted positioning. By afternoon, collectors would test it during matches. By evening, I’d see their feedback in Slack.
“This saved me 9 minutes per frame.” “My hand doesn’t cramp anymore.” “Eyes stay on video, not the mouse.”
That feedback loop—collectors telling us what slowed them down, seeing it fixed the next day—became the foundation for everything we built over four years. Not from management validation or product roadmaps, but from the people doing the actual work shaping the tool directly. When you ship for people who trust their feedback will change tomorrow’s build, architecture stops being abstract.
The Partnership: Domain Expertise Meets Systems Thinking
Ali had spent years analyzing sports data—he could articulate possession rules, drive sequences, phase transitions. I’d been thinking about systems since I was 14, reading “Pragmatic Programmer” on Egyptian buses, squinting at my phone screen.
Week one, Ali and I sat with VSCode open. He spoke rules aloud, I typed them as text:
start → [middle] → break carry flight loose As I typed what Ali dictated, I realized: I wasn’t writing documentation. I was encoding his mental model as executable text. That’s when it clicked: the dataspec can’t be code. It has to be data we can iterate without deploys.
That partnership—domain expert + systems thinker—is why the DSL approach worked. Without Ali’s mental models, I’d have built generic forms. Without my systems thinking, his knowledge would’ve stayed tacit.
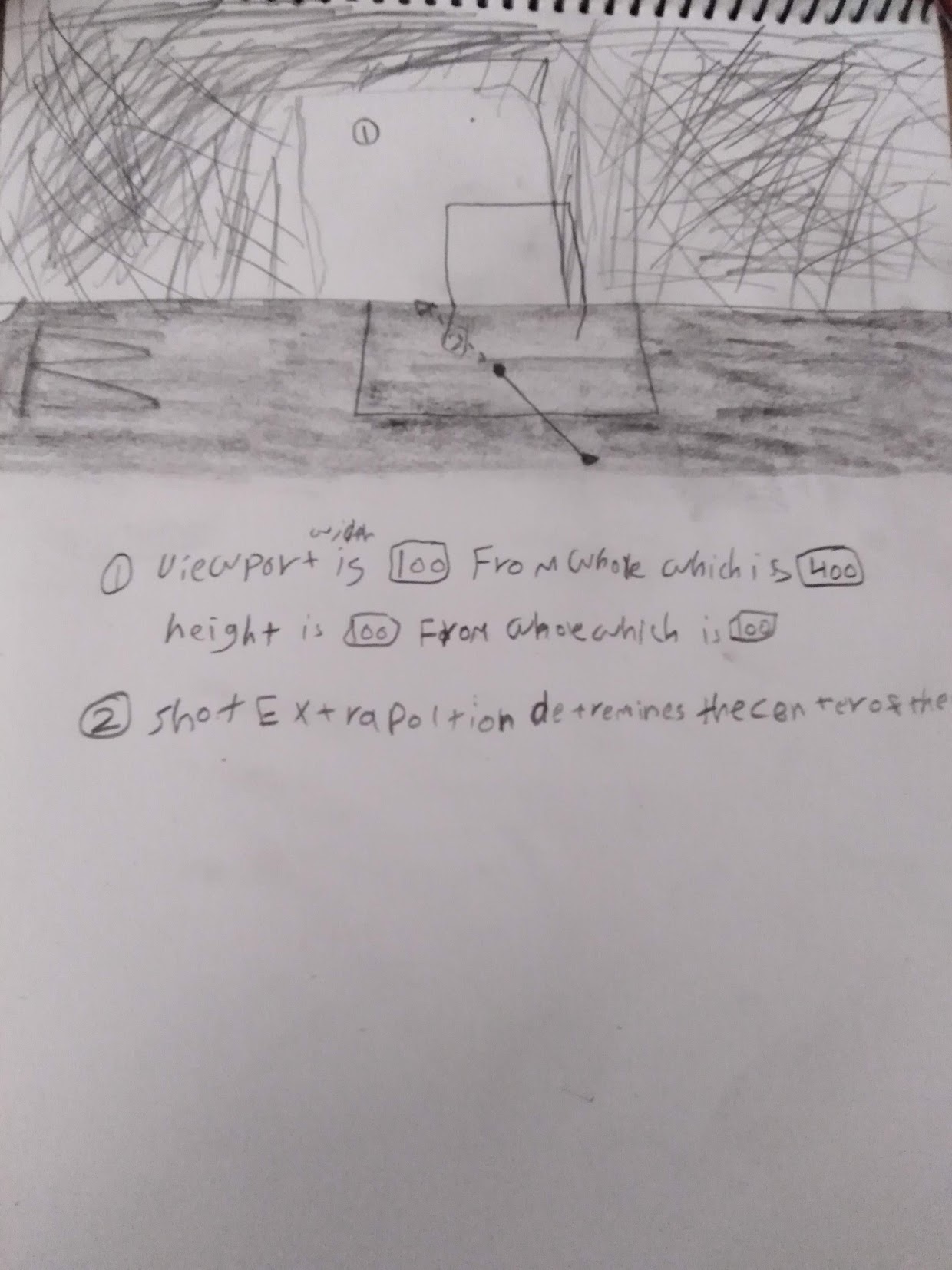

Week One sketches (2018): From these rough drawings to production tool in days, evolving with customer-driven features like Liverpool's goalkeeper reaction tracking
The Two-Merge Bottleneck
Two collectors, same match. Hours after the final whistle, they’re still arguing.
“That’s a recovery.” “No, interception—he anticipated the pass.” “But possession hadn’t transferred yet.”
Same foul—collector A logs “foul-committed, 0.01s.” Collector B logs “foul-won, 0.011s.” Same moment, different perspectives, imperfect timestamps. Hours spent pairing: which events describe the same thing? Then validate chains. Then location, freeze frames.
The tool allowed perspective-based collection. Collectors paid the pairing cost afterward.
Before: Sequential Collection
graph TD
subgraph live["⏱ Offline Match (12h)"]
Start["Match begins"]
Start --> HomeCollector["Home collector"]
Start --> AwayCollector["Away collector"]
end
subgraph post1["⎇ First Merge"]
HomeCollector --> Merge1["~1 hour"]
AwayCollector --> Merge1
end
subgraph post2["⚖ 2 Collectors x 4h"]
Merge1 --> HomePost["Validation"]
Merge1 --> AwayPost["FreezeFrame"]
end
subgraph post3["⎇ Final Merge"]
HomePost --> Merge2["~1 hour"]
AwayPost --> Merge2
end
Merge2 --> Complete["Match complete
~12h total
~20 man-hours"]
classDef bottleneck fill:#FFFFFF,stroke:#DC2626,stroke-width:3px,color:#0F172A,font-weight:600
classDef collector fill:#FEF3C7,stroke:#F59E0B,stroke-width:2px,color:#78350F
classDef processor fill:#DBEAFE,stroke:#0EA5E9,stroke-width:2px,color:#0C4A6E
classDef system fill:#D1FAE5,stroke:#10B981,stroke-width:2px,color:#065F46
class Merge1,Merge2 bottleneck
class HomeCollector,AwayCollector collector
class HomePost,AwayPost processor
class Start,Complete system Text alternative
Offline workflow taking 12 hours: Home and Away collectors work in parallel. First merge reconciles collection conflicts (~1h). Then 2 collectors work in parallel (4h each) on Validation and FreezeFrame. Final merge reconciles post-processing conflicts (~1h). Total: ~12h wall-clock = 20 man-hours.
After: Concurrent Collection
graph TD
subgraph live["⏱ Live Match (Real-time)"]
Start["Match begins"] --> Base["Base Event"]
end
subgraph enrich["⫴ Up to 12 Parallel streams"]
Base --> E1["Extras"]
E2["..."]
Base --> E3["360 FF"]
end
subgraph merge["⎇ Automated Merge"]
E1 --> M["No conflicts"]
E3 --> M
end
M --> Complete["Analytics from first moment
ends real world time"]
classDef atomic fill:#FEF3C7,stroke:#F59E0B,stroke-width:2px,color:#78350F
classDef derived fill:#DBEAFE,stroke:#0EA5E9,stroke-width:2px,color:#0C4A6E
classDef system fill:#D1FAE5,stroke:#10B981,stroke-width:2px,color:#065F46
class Base atomic
class E1,E2,E3 derived
class Start,M,Complete system Text alternative
Live real-time workflow: Base events created during match with up to 12 parallel enrichments (Extras, … , 360 FF) based on desired collection granularity and speed SLA. Automated merge with no conflicts. Analytics available from first moment, ending at real world time.
The merge tax scaled linearly with collectors. At 100 collectors, two product managers mediated conflicts manually—tedious but manageable. At 1000 collectors? The math broke. Manual conflict resolution couldn’t scale without proportional staffing increases, blocking market expansion.
What collectors needed: prevention during collection, not reconciliation after. We architected the tool to make ambiguous interpretations structurally impossible—if you can’t express it in the UI, you can’t collect it wrong.

Real-Time Collection: The 2am Test
We tested for months before committing to broadcasters. “Real-time” wasn’t a feature—it was an obligation. One failure during a live match = lost client.
I’d start at 10am, leave at 3am. Not grinding for grinding’s sake—I needed to see what broke when collectors rotated shifts. The edge cases revealed themselves at 2am: World Cup match goes into extra time, VAR ref review not in the spec yet—iterate, release, loop until broadcasters got what they needed.
Ali stayed nights for company. Not to supervise—he wasn’t debugging TypeScript with me. But he understood the stakes. Broadcasters needed real-time commentary data. Collectors needed tools that didn’t break at 2am when fatigue set in.

That’s when we’d debug together: Adham tracing the Kafka lag, me testing state machine transitions, Waheed debugging the metadata, with a tired collector who just wanted to finish the match and go home.
Architecture: Three Systems in Parallel
Understanding the business value explains why we built this. Now: how did architectural decisions enable scale and multi-sport expansion through separation of concerns?
Three systems evolved in parallel:
Domain Logic as Configuration — Product managers owned the rules
Remember week one—Ali and I sketching start → [middle] → break as sequential chains while I typed in notepad? That’s when it clicked: the dataspec can’t be code. It has to be data we iterate without deploys.
Product managers needed to express domain logic—entry validation, sequencing, aggregation—in readable syntax that compiled to execution. Rules as data, not code.
Atomic events (passes, shots) aggregated into derived facts (possession phases, drives, turnovers). Store unchanging truth, recompute everything when the dataspec evolved.
Production revealed ball possession had states—carry, flight, loose—not sequence positions. Early classification asked ‘is this recovery offensive?’ Later versions asked ‘whose team has the ball?’—simpler question, impossible to misinterpret. Pass tracking shifted from outcome-based (did it complete?) to state-based (ball in flight → resolution). Flight became its own phase with clear resolution paths.
The payoff came in 2020. When we expanded to American football, product managers wrote drive segmentation rules using the same patterns. New sport, same architectural separation. Zero engineering bottleneck.
Without DSLs, every new rule required engineering deploys. With DSLs, product managers shipped independently—velocity without correctness trade-offs.
Live-Collection-App — State machines owned correctness
The 2am Test taught us: World Cup extra time, exhausted collectors, keyboard glitches, WebSocket drops. When humans are depleted, tools must guide them.
The industry-standard video analysis tool (Dartfish) forced button-heavy mouse clicks with rigid keyboard shortcuts—50+ event types mapped to 40 keys, memorized regardless of context.
We built context-aware: press ‘P’ for pass, the system knew valid pass types for that player’s position. One option remaining? Auto-filled and advanced. Collectors touch-typed like Vim users. Eyes on video, hands on keyboard.
Ashmawy, Andrew, and Shash built computer vision for automated position detection—collectors corrected edge cases.
When it mattered most, the architecture protected collectors: dataspec validated inputs, state machines prevented illegal sequences, DSLs defined legal transitions. Errors became structurally prevented, not just caught.
Backend Evolution — Event graphs owned time
Event Graphs: Sequential event logs couldn’t answer “what caused this turnover?” We needed both temporal relationships (clearance BEFORE recovery) AND logical relationships (clearance CAUSED loose phase). Events formed directed acyclic graphs with typed edges—enabling timeline replay and root-cause analysis for data quality debugging.
Waheed’s Claims Breakthrough: Match metadata from thousands of collectors meant inevitable conflicts—same player, different spellings. Waheed built claims-based metadata resolution. The insight: metadata isn’t key-value pairs, it’s claims from actors. System detected conflicts automatically, routed 1-2% ambiguous cases to the 5-person metadata team. They resolved once via claims interface—system cascaded to all dependent data. The team handled ambiguity; the system handled scale.
Backend Evolution: Month one: Omar Negm built the single Go endpoint called sync—batch, offline. In year two (2019), when Omar left to teach kids software, Adham joined and designed the evolution to Kafka as persistence center, event logs as foundation—enabling real-time collection at broadcaster scale.
The Dataspec Velocity Tradeoff: How Do You Change Rules Without Invalidating History?
By 2020, we had two years of historical matches. Thousands of games, millions of events. Then we realized: “possession” in 2020 meant something different than “possession” in 2018. We’d learned more about the sport. The rules evolved.
Most systems would version the data: v1 events stay v1, new matches use v2. But that breaks analysis—you can’t compare 2018 Liverpool to 2020 Liverpool if possession definitions changed between them.
The solution: tiered evolution. When the dataspec changed, we’d backfill historical data through the new rules—recomputing derived facts from the atomic events we stored. The graph structure made this possible: we knew what cascaded when one definition changed.
The dataspec itself had to be uncertain. From week one, we knew: not if we’d iterate, but how often. Our historical data needed to evolve with our understanding—not versioned snapshots frozen in time, but living data that grew smarter as we did.
Distributed Ownership: Learning to Scale
What enables fast iteration at the start? Simplicity—ship twice daily, direct collector feedback, zero coordination. As complexity grew (DSLs, state machines, metadata resolution), the question shifted: how do you maintain velocity with a team? The technical architecture took three years to evolve. The harder part: building a team that could iterate beyond the initial design while learning to distribute ownership.
The Breakthrough: Distributed Ownership
Adham advocated for Kafka in year two. I resisted—unnecessary complexity. His counter: the domain will demand it. By year three, he was right. Event streaming became essential for parallel collection and historical corrections.
When Waheed, Hadeel, and Abdallah joined, something shifted. They didn’t just implement—they took ownership and iterated beyond what we started with. Waheed transformed conceptual sketches into production systems. Hadeel hardened prototypes for live match scale. Abdallah evolved workflows I thought were complete. They felt the same urgency to serve collectors directly—that partnership from week one had become distributed ownership.
Epilogue: Hudl Acquisition (2024)
In 2024, two years after I left Egypt, Hudl acquired Statsbomb.
Hudl is the industry standard—the platform most college and professional teams use globally for video analysis and performance tracking. They didn’t acquire Statsbomb for the data alone. They acquired the collection system, the DSLs, the real-time infrastructure that enabled 5000+ collectors to work concurrently.
The patterns Ali and I sketched in notepad during week one became valuable enough for an industry leader to buy. The architecture that emerged from serving collectors directly, from watching what slowed them down and making it faster, had legs beyond what we imagined.
Impact: Before/After (click to expand)
What actually changed on the ground? Here’s the operational transformation from Dartfish baseline to production at scale.
— A.Magdy, 360 LeadWith Dartfish, 12 minutes just to freeze a single shot. Now we freeze every event in the match—passes, tackles, everything. The tool made this scope possible.
Before
- New sports: 12 months blocked
- Rule changes: 5-day engineering cycles
- Conflict resolution: 8 hours
After
- New sports: day-one deploys
- Rule changes: 5-minute deploys
- Conflict resolution: eliminated
2018
Soccer, Offline Collection
~100 collectors, offline tagging
2020
Live Collection Breakthrough
Live collection, 1000 collectors
2021
American Football Expansion
American football expansion
Post-2022
Scale Beyond Departure
5000+ by acquisition
What Made This Possible
Non-linear leverage
Non-linear scaling without proportional staffing increases. The 5-person metadata team (Muhanad led ops context) queried pending conflicts, resolved once via claims interface, and the system cascaded updates to all affected events.
Minimal engineering bottleneck
When we expanded to American football in 2020, product managers wrote new dataspecs and grouping rules. Engineering only intervened for state machine edge cases (e.g., possession turnover during penalty review—an NFL-specific complexity).
Collector experience transformation
Keyboard flows built muscle memory. Contextual mappings reduced cognitive load (press ‘P’ for pass, but context changes based on phase). Computer vision assisted bounding box input, reducing manual pixel-perfect clicking.
Client customization through configuration
Different granularity requirements—basic event tracking or advanced positioning data with x/y coordinates—handled through dataspec configuration, not separate codebases.
From 100 to 5000+ collectors, product managers shipped new dataspecs without proportional engineering investment, though complex state transitions occasionally required technical collaboration.
Lessons: What Transfers? What Only Worked Here?
Four years, three systems, distributed ownership learned the hard way. Which principles transfer to other domains? Which only worked because of sports analytics constraints?
What I’d Change
I had to leave Egypt in early 2022. Not a choice I wanted—leaving Ali, Waheed, Hadeel, Abdallah, the collectors, the work still unfinished.
Adham had already left months before. His absence made staying harder—then circumstances forced me to leave. The backend partnership, the late-night Kafka debates, the distributed ownership we’d just started scaling—it fragmented before I left.
By then: 5000+ collectors remotely, internal DSLs shipped and scaling, American football expansion working. But the customer-facing DSL—the one that would let clients define their own derived facts without us—remained unfinished when I left.
The people I worked with deserved more time together. The systems we built deserved to reach their full potential. Neither happened.
If I Could Rewind
What if distributed ownership wasn’t a year-three discovery but a founding principle?
Adham, Waheed, Hadeel, Abdallah took concepts—state machines, DSLs, event graphs—and evolved them. That emergence happened despite late investment, not because of early planning. By the time distributed ownership became structural (year three), half the team had fragmented.
The harder pattern: teams don’t scale architectures—they reveal what architecture should’ve been from the start. Knowledge centralization creates beautiful bottlenecks, no matter how elegant the separation of concerns.
What Month Six Revealed
The bounded contexts existed in the domain from day one—match metadata, event collection, people coordination, media management, contextual aggregation were always separate concerns. We just didn’t have the fluency to recognize them yet.
Month one, everything felt coupled. Month three, listening to how collectors, analysts, and product managers talked revealed distinct vocabularies: metadata queries used different language than event recording, coordination had its own mental models separate from data quality. Month six, those linguistic boundaries became undeniable architectural seams.
The domain had structure all along. Developing fluency to recognize it took three months of production work. You can’t shortcut that curriculum—event storming from day one would’ve drawn boundaries around our assumptions, not the domain’s reality. Some architecture must be discovered through listening, not imposed through planning.
When These Patterns Apply
These aren’t universal truths—they worked because of specific conditions:
Scale: 100k events/minute peak, 5000+ collectors processing live matches
During peak live match time, the system processes 100,000+ atomic events per minute—touches, passes, tackles, runs—streaming through arbitrary validation layers in real-time. With 100 collectors, manual coordination could absorb this velocity. At 1000+ collectors, 2 product managers couldn’t handle 50+ daily dataspec questions while the spec evolved. Today at 5000+ collectors processing live matches simultaneously, architectural separation isn’t optimization—it’s the only way to handle this streaming intensity without engineering bottlenecks.
Domain: Tacit expertise worth externalizing
Sports analytics, medical diagnosis, legal review—domains where experts have tacit knowledge worth externalizing. The more complex the expertise, the more value in DSLs that let non-engineers express rules.
Multi-variant: N configurations, not N codebases
Multiple sports, client customization, regional variations. When every customer wants different behavior, configuration prevents maintaining N codebases.
Meta-lesson: Context determines what works
More domain knowledge → better problem diagnosis → better architectural decisions → concepts that create value instead of complexity. Context always determines what works.
Behind the Scenes
Evolution: From 100 collectors doing offline tagging (2018) to live collection at scale (2020), expanding to American football (2021) and ultimately 5000+ collectors by acquisition (2024).
















